
Are Boosting Algorithms the new baseline model for your Tabular data? Part 1
My usual ally when dealing with tabular data is glorious Random Forest (RF). You can try it in your data without regret and probably RF will give you a very good baseline solution without spending time tuning the algorithm. (I truly believe Leo Breiman is a kind of god at the same level of Hinton. Random Forest is a ensemble learning algorithm which uses the bagging strategy. In general the idea of RF consist of generating different decision trees on sample subsets of the original dataset. There is, however, an alternative strategy about ensemble learners which is boosting. In boosting decision trees the idea is to “concatenate” several decision trees generated using residual (or misclassified examples). You can think in a sort of pipe between different trees.
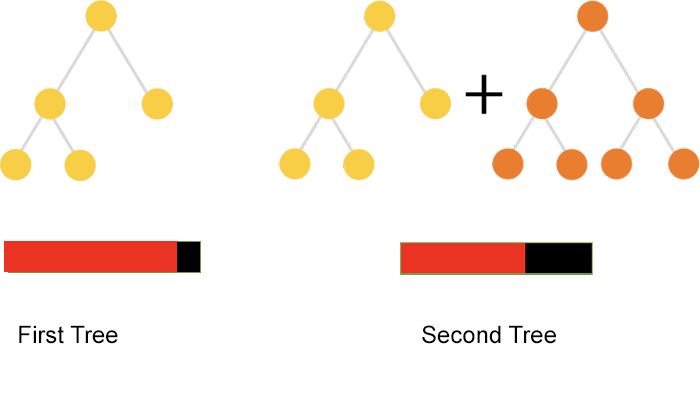
Given a classification problem, boost algorithms constructs a decision tree from observed data. Misclassified examples are then used for building a second tree, whose results are added to the first with some weight. The process is iterative and it can continue no improvement is observed.
Notice: Boosting and Bagging can be applied to any weak learner and not only decision/regression trees.
One of the famous boost algorithm is Adaboost proposed by Freund & Schapire. Some boosting algorithms such Adaboost used weights for considering the importance of each tree, while other used the gradient for minimizing the error. Friedman’s article from 2002, proposes an adaptation of boosting algorithms using stochastic gradient descent over the residual information.

Pseudo code of boosting algorithm as described in ISLR
The major inconvenience of boosting algorithms is they are prone to overfitting the data. To avoid the problem, they need a lot of hyper-parametrization, which of course consumes a lot of time. 😒
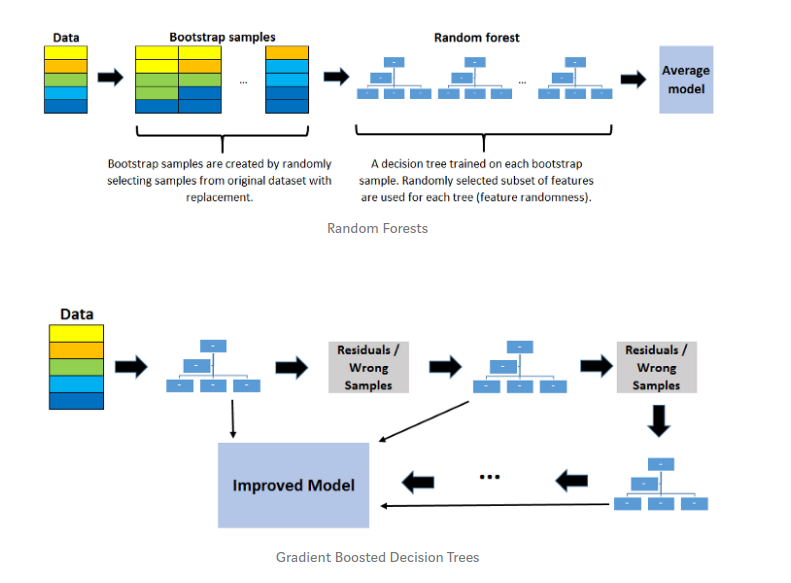
Several boosting variants have emerged to deal with these inconveniences. A couple of years ago, XGBoost was the top leading boost algorithm . It had a lot of success in several Kaggle competitions. Now, you can find several other very good alternative such as LightGBM from Microsoft research and more recently catboost from Yandex, a Russian tech company.
All these new boosting algorithms have made considerable improvements regarding speed and avoiding overffiting. An interesting aspect is all of then support multiple processors and even the use of GPUs during training process.
Algorithms such as catboost have put a lot of effort in helping the user during the hyper-parameters selection. The algorithm starts with a default set of parameters learned from your dataset. In addition catboost includes several techniques for early stopping. A well known strategy to avoid the overfitting. Catboost as well as XGBoost and LightGDM have packages for python and R. And in the case of Catboost they also provide a CLI version of the algorithm. Another major contribution about catboost if they handling of categorical data. You can pass the index of your categorical variables to the algorithm and catboost will use very efficient transformation in order to improve de execution time.
Here is a list of resources to start with boosting:
-
A set of minimal posts about algorithms works. Most of them are introductory material.
- An explanation about how Boost works explained in a very simple way. Something a 2 years old can understand.
- A more deep explanation about Gradient Boost algorithms including the differences between Random Forest Bagging approach.
- A very practical writting about the differences between Random Forest and Gradient Boosting Algorithms. When, why and how use each one.
- A post discussing the different approaches used for handling categorical variables in the different gradient boost implementations. The differences in the approaches could impact in the overall computing performance.
-
The short paper from Freund & Schapire explaining the basic concepts of ADABoost. Also the articles from Friedman about the Gradient Boosting algorithms from 1999 and 2000. Notice that the last two articles are a little bit technical.
-
Don’t forget to check documentation and information from the gbm R package. Where regular and stocastic implementation of gradient boosting machines are implemented.
-
A very recommended post about how Boost algorithms work by a Kaggle Master. I personally recommend this article, with a practical point of view without missing the important concepts behind Boosting machines.
-
A nice post discussing the differences between XGBoost, LightGBM and Catboost
-
A research article about catboost. The new boosting algorithm coming from mother Russia.
-
A video tutorial for using catboost. In the video, one of the authors of catboost exposes the main feature using a hand-ons approach. Notebook available.
I’m thinking about giving a try to catboost, and for sure I will post a very small review of the algorithm. Who knows.. may be it can beat Random Forest as the favorite choice when using tabular data..