

Machine Learning Experimental Design 101
Thanks to Gabriel Caffaratti and Jorge Guerra from LABSIN for your help and feedback in writting this note.
This post is part of a series of posts about experimental design in machine learning: Experimental design 102
The standard workflow
Experimental design is a fundamental skill for any machine learning practitioner. No matter if you work in the academy or in the private sector, from time to time you will require to perform some sort of evaluation of your model. At some point, you should convince customers or reviewers that your model results have a certain amount of generalization and it is capable of dealing with future (not seen) scenarios reasonably well.
Fortunately for us, the experimental design for evaluating the performance of a machine learning model is well known. The process is described in Figure 1. There, you basically have a dataset split in training and test (usually a 70/30 ratio). The 30% of the data should be left aside and ideally never touched until you have finished with your model tuning. On the other hand, the 70% of the data could be used for training/validate your model and/or conduct a hyper parameter search for tuning the model. The are several approaches during the validation phase (see chapter five about resampling methods from ISLR for more info), but using cross validation with k folds is perhaps the most widely used. I personally like to perform 2x5 resampling, which basically means applying a 5 folds cross validation repeated 2 times.
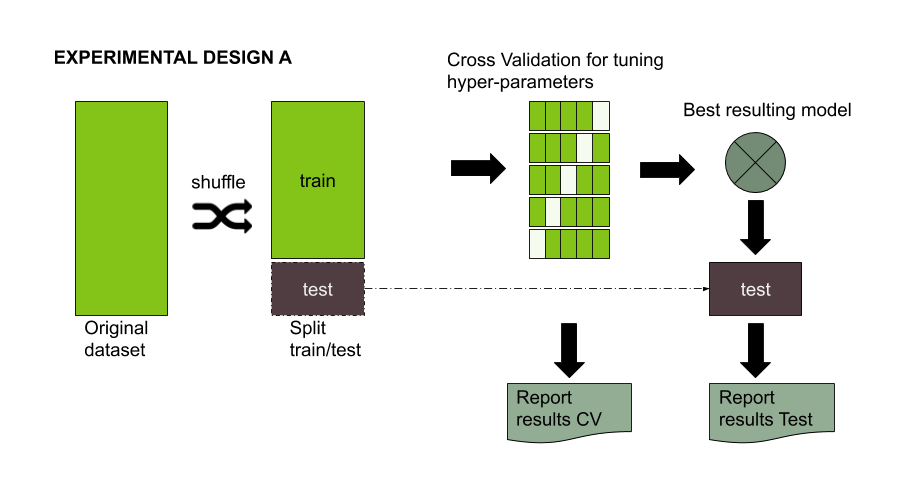
Figure 1. Standard experimental design for evaluating the performance of a machine learning model.
When you have finished with your model evaluation you report your results on CrossValidation (CV Report) and on test (Test Report).
The CV Report
The CV results give you information about:
Model Variance: No matter if you apply a two folds or a ten folds strategy on your training data, you definitively need some sort of repetition for evaluating the variability observed in your model when using different datasets for training. Here, you will need to report the mean and standard deviation of any of the model configurations you have tried (perhaps in conjunction with some visualization of the error distribution such as boxplot or violin charts)
In any case, CV results will provide you with a better estimator of the generalization error of your model and as stated by (Dietterich, 1998) allow you to perform stronger tests (statisticaly-based) to compare different models.Overfitting: Sometimes your model performs extremely well during your CV evaluation but the performance could be considerably worse during the test. Therefore, reporting CV results can give you a clue about possible overfitting problems. Ideally, when using CV you reduce the chance of overfitting a model, but that does not mean overfitting can not occur. See article from Cawley & Talbot (2010) for an analysis of the overfitting problem selecting your model using CV and the possible way to avoid it. Notice that overfitting is not the only explanation behind discrepancies between CV and test reports. This model performance mismatch can be explained by simple reasons such as your training data is not representative of the problem, or maybe that the sample size is too small. Alternatively, it can be caused by the stochastic nature of the algorithm used (e.g. Neural Networks). In both cases the analysis of the sample mean and the standard deviation over several repetitions using training data can help you to differentiate each cause. See this short post about the topic here.
From the information provided by the CV report you will finally choose the “best” (more adequate) model for dealing with your machine learning problem. Notice that sometimes the definition of “best” can not be easily established.
The Test Report
The Test results give you information about:
- Independence: The main reason for using a test set is that you will have an idea of how well the model is expected to perform in real life. Since any decision regarding the model generation should have NOT been made considering the information provided by the testset, then you would have an unbiased idea of the model performance when deployed in the real world.
Ideally, your result in the test set should be within the range of results observed in CV Results, however, as stated before, such a situation not always happens. When analyzing test results, the model performance mismatch can be caused when there is no correlation between train and test sets. In other words, the test set you are using has completely different examples from trainset. If such is the case there is nothing the model can do. This situation is referred as Covariate shift, when predictor variables have different characteristics (distribution) in train and test datasets.
A appropriate test set should follow the same predictor variable distribution, BUT it should have a certain degree of uncorrelated examples. Moreover, to collect evidence for supporting your estimated model performance , you should evaluate your model on different independent test sets.
Conclusions:
- No matter the situation, you should always repeat the evaluation of your model on different datasets. Resampling techniques are the most common strategy.
- Always report CV and Test results. Both reports provide you with valuable information for a better estimation of the model’s overall performance.
- Testset shouldn’t be used for taking any decision about your model. You should evaluate your model on testset as little as possible. (just one time is ideal)
List of Resources:
Articles about CV and overfitting:
About model performance mismatch and Covariate Shift:
- A very simple and clear series of posts about dealing with Covariate Shift
In addition, I have found this very nice book about experimental design for computer sciences: Empirical Methods for Artificial Intelligence (MIT Press). Haven’t read it yet. But it sounds interesting 😉