
Machine Learning in Production
Thanks to Seba Perez From DHARMA and Tincho Marchetta from LABSIN for providing me with valuable resources about the topic.
Machine learning has moved from academia to industry very fast. In fact, machine learning has become more like a product-oriented than research task. Far away are those days when you tested your new machine learning model in a well-known dataset with the idea of improving a performance metric. Now, you have to test your models against real life!!!. And perhaps the most important thing is, they have to make money to your company 💰.
Back in the days, you had to implement your own version of the algorithm or perhaps use one of the very few libraries available. Things such as scalability, reliability and availability were completely out of the scope for a traditional machine learning researcher.
Developing a microservice? Containerization of your models? Out of the question!! 🤔
Implementing an architecture to support data drift? What about a retraining pipeline? NO WAY!! 😱

The fact is that developing machine learning models now requires expertise in several areas beyond the traditional programming and statistics/math. As a consequence, several new roles (with fancy new names) have emerged in the hot market of machine learning products.
In 2020, WORKERA.AI published a report about Data Science/Machine Learning careers pathways. The report provided some insights about the responsibilities of each (new) role in the development process of a machine learning product. I copied/stole the following chart from the report.
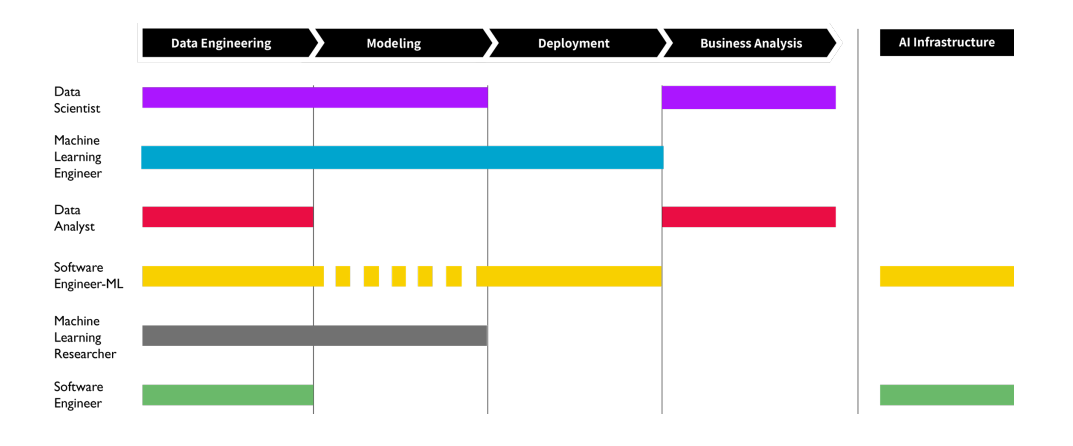
Figure 1. Five roles involved in the machine learning production workflow.
The reports recognizes five roles. However, there are some specialists in this new field of developing machine learning products such as Chip Huyen, who considers that there are some other important roles beyond those mentioned in the report. For instance, roles more oriented to hardware such as multiprocessing or GPU programming are not considered in the report.
Workera recently published a report on AI career pathways. It doesn't mention hardware. I also don't see the difference b/w SWE-ML & ML Engineer. But it highlights some important distinctions.
— Chip Huyen (@chipro) January 10, 2020
I also like @josh_tobin_ talk on the structure of AI teams https://t.co/X6eHv8sskA pic.twitter.com/KysDChOjgR
To keep this post short I will only focus on the differences between Data Scientist, Machine Learning Engineer and Machine Learning Researcher. Please keep in mind that the following is just a certainly biased and simplified description of the roles.
Machine Learning Researcher: A role focused on the development of new algorithms. Strong math and statistical background are required. A researcher usually works with a set of benchmarking datasets and is not particularly motivated to do dirty work, such as data cleaning/mangling, etc. You wont find many companies motivated to support this role, except, of course, those companies with a large research department. (Google, Facebook, Amazon, etc.)
Data Scientist: A role focused on the development of business-oriented solutions. When a company hires a data scientist expects to extract valuable information from its data for making big money in the future. Sure you have seen Conway’s Venn diagram about Data Science. Programming skills, math and business knowledge are fundamental skills for doing data science.
Figure 2. A very low resolution version of Conway’s Venn diagram about Data Science. Google for better versions.
Depending your background you will have more programming or more math skills, but the business knowledge is something that you will definitively need to acquire at some point. Otherwise, you wont be able to guide the questions during your data analysis. A Data Scientist is not afraid of dealing with messy datasets, building scrapping tools, implementing interactive visualizations and of course generating a machine learning model. But he/she will usually try very well established algorithms provided by third-party libraries. Developing a new machine learning algorithm is definitively out of the scope of the role.
Machine Learning Engineer: The two previous roles have been well defined for several years. But the Machine Learning Engineer role is something relatively new. Under this role, not only programming and math skills are required, but also SOFTWARE ENGINEERING. Please take a moment for imaging the situation when you, a Data Scientist hired by some company, come out with and brand new and incredible model capable of identifying potential clients for company’s main product with 99.99% of accuracy. YOU ARE AMAZING !!! 👓
But then comes the questions from the management area:
- How can I use the model if you are not here?
- Can be deployed in our cloud service?
- Can WE retrain the model with new data?
- Once we detect a performance decrease what we can do?
These certainly valid questions are the cause behind the arisen of the Machine Learning Engineering role. In a traditional Data Science job, you were prepared to implement some interactive dashboards (probably using shiny or some other high level tool) for interacting with the valuable information you found from company’s data. But including your model inside the company cloud infrastructure is something completely different. Now, you will need to move from your comfortable Jupyter notebooks and implement a Microservices Architecture to deploy not only your resulting model but also the complete preprocesing pipeline required for training it. The architecture should scale according to the company expectations. And perhaps in one or two years a complete refactoring will be required. Obviously, the company will want to reuse the source code, so you will need to follow company rules regarding writing code for production.
These are just some aspects related to machine learning engineering roles that requires a strong background in software engineering. Today, Machine Learning Engineering is the job most demanded by companies in the machine learning scene. You still will see job offers for DATA SCIENCE positions but, if you look carefully, you will see they are actually looking for machine learning engineers. Thinking a little bit about it, it makes sense. Companies don’t want algorithms researchers or depending of a data scientist for updating the model every time new data is available. They only need a way of extracting valuable knowledge and put that knowledge at the service of their own goals.
So basically, having a certain degree of software engineering skills is definitively a must for applying to the so-called data science positions.
The following are just a small set of resources discussing different aspects of the machine learning role.
-
A medium post discussing the different challenges when deploying machine learning products. The post is based on a paper from 2020 published in Arxiv. Six fundamental aspects are covered: Model reuse, Effective collaboration between researchers and engineers, Outlier detection for better predictions, Handling concept drift, End-user trust, Adversarial attacks.
-
This post also from Medium discusses the different approaches to be considered when deploying machine learning.
-
A white paper from Google discussing the hidden technical debt in machine learning systems. I personally recommend the anti-patterns sections of the article.
-
A book from Andew Ng that provides a very practical perspective to machine learning. In fact the book deals more with Deep learning than machine learning. The book is very short and easy to read and provides a set of recipes totally oriented to machine learning teams. Warning: The article don’t deal with software engineering issues but still is highly recommended if you want to have a practical approach to machine learning!
-
Chip Huyen is lecturing a new Stanford course about Machine Learning Systems Design (CS 329S). This is the first time the course is lectured, so I have no feedback about it. However, the syllabus is available, so you get your own idea about the course.